
Book review: The Thousand Brains Theory
A review of Jeff Hawkins's theory of intelligence.

Even though ChatGPT is impressive, most people would agree that it’s not intelligent in the same way a human is. It’s great at writing stories about cats, but it doesn’t know what a cat is. Hell - it doesn’t even know what a word is! All it knows is tokens. And all it can do is pick the best next token. It’s not ChatGPT’s fault these tokens make some kind of sense to you. It never tries to make sense. It only tries to pick well.
The same can be said for any other machine learning model. These things are just really good at picking. And that leaves most people in the field satisfied with their current approach. The approach is, “we don’t care whether this is how the human brain does it as long as it works”.
Jeff Hawkins is the opposite. He doesn’t care about anything merely “inspired” by the brain. He wants to get at the real thing and he has spent the last decade(s) developing a theory of intelligence. “A Thousand Brains” is his attempt to put everything together. Reading it made me understand the brain better and gave me an idea of how the theory of predictive processing could work on the level of a neuron.
Old brain, new brain.
All this old-brain-vs-new-brain stuff is not just pop science. There is a clear anatomical distinction.
There is the super old brain - the part that even frogs and reptiles have. It regulates the basics like movement, breathing, and digestion. Then the somewhat old brain - the part that we share with monkeys and other mammals. It regulates emotions and social status. And finally the new brain - often called the neocortex. It does all the exciting stuff. Vision, language, math, music, science, engineering…. it’s all in the neocortex.
So next time you try to remember something about brain anatomy, just think “frog, monkey, human” and you’re halfway there.

The new brain (human) doesn’t have a direct connection to musculature, therefore it doesn’t control movement directly. If it wants you to do something it needs to signal to the old brain (monkey + frog). Sometimes the old brain listens and sometimes it doesn’t. For example, you can hold your breath (frog allowing human to control movement), but if you hold it for long enough the old brain takes over and just forces you to breathe (frog overruling human).
Hawkins makes some good points on why his theory is focused on the new brain only. I’m not going to reiterate all of them here. Just know, that intelligence is in the neocortex. We only focus on the neocortex from now on. If we can recreate the neocortex, we can recreate intelligence.
The big idea is that the neocortex consists of many copies of the same thing.
A slice of vision cortex looks just like a slice of language cortex. The only difference is what it is connected to. Connect a piece of neocortex to the eyes and you get object detection. Connect the same piece to an ear and you get melody detection. There’s tons of evidence to support this. In blind people, for example, the part of the neocortex that would have been responsible for vision just assumes other tasks, like hearing or touch.
Ok, so the neocortex consists of many copies of the same thing - then what is the thing? Hawkins's answer: the cortical column. A cortical column is a 1 x 1 mm piece of the neocortex, 3 mm deep. Here’s an image to get a sense of it:

There are roughly 150,000 cortical columns in the human neocortex. Mice have one column for each whisker, which is cute, but hardly relevant. Here is a representation of different types of neurons in a column:
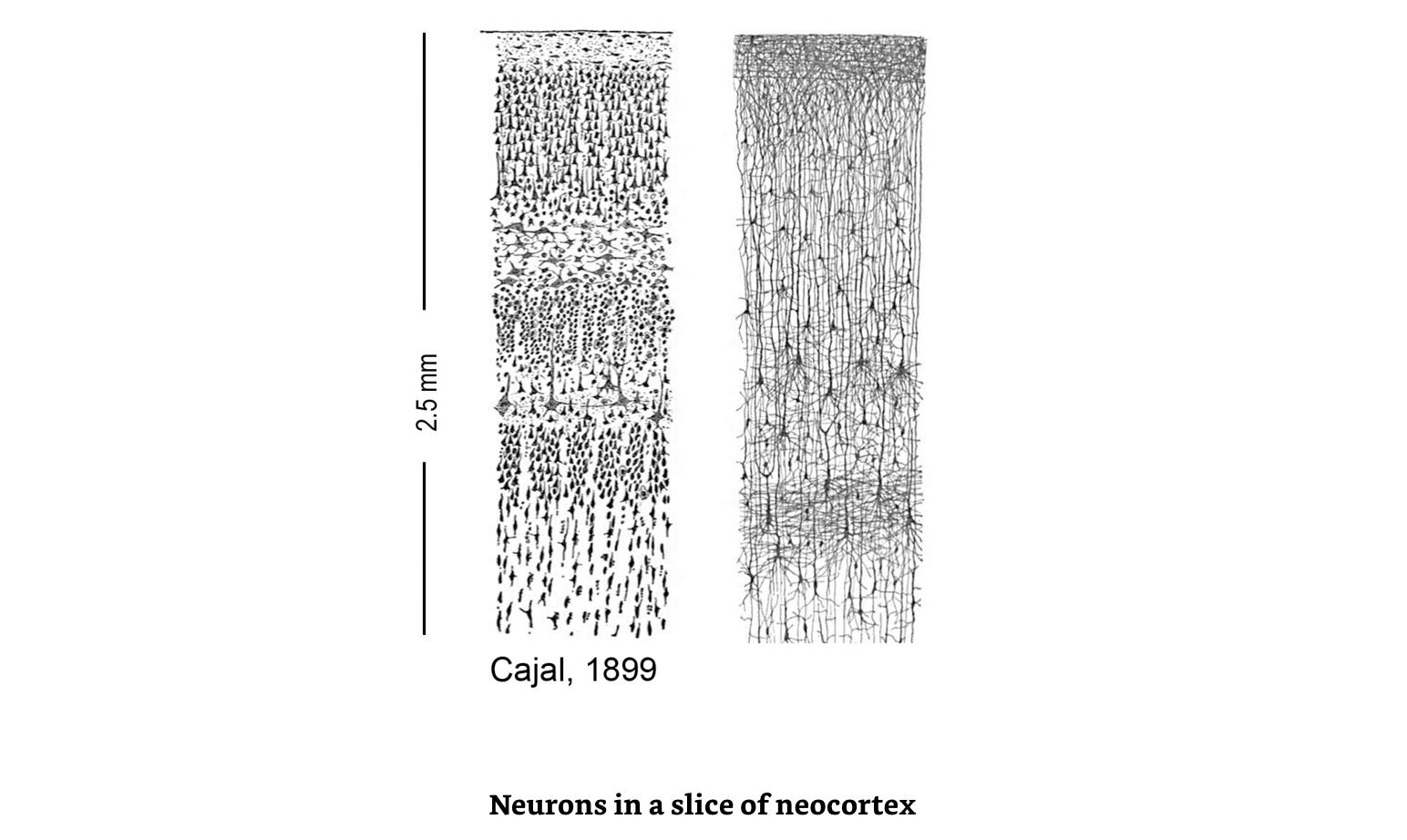
The black spidery-looking dots are neurons. There are many more neurons in a column than are illustrated in that picture. A column is made up of roughly 100k of them.
The actual sizes of these columns vary. It’s biology. Everything is smushed and squashed. You can’t clearly distinguish one column from another when you look at the neocortex under the microscope. We only know they exist, because all the cells in a column will respond to the same part of the retina or the same patch of skin. All cells in some other column will respond to some other patch of the retina or some other patch of skin. This grouping is what defines a column.
Here is a 3D reconstruction of five neighboring columns in a rat:

I’m trying to give you multiple visual representations of a column here because it’s our main protagonist. In Hawkins's opinion, a column holds all the basic ingredients of intelligence within. The more columns, the more intelligence. If we buy that, the road to intelligence becomes quite straightforward:
Reverse engineer a cortical column.
Make lots of copies.
That’s it. You have built intelligence.
I don’t know how much consensus there is about this idea, but it’s exciting and it makes sense. Evolution wanted our neocortex to do lots of different things, like invent language, build tools, write songs... If you want to be able to do so many different things, you need a general learning machine. Being able to learn practically anything requires the brain to work on a universal principle. The cortical column might hold that universal principle within.
Cortical columns are prediction machines and they learn models through movement.
Hawkins never mentions Andy Clark or that there is a theory of predictive processing. I don’t know why. His theory goes together so well with the theory of predictive processing that I feel I just have to mention it here. A quick recap:
The brain is a multi-layer prediction machine. All neural processing consists of two streams: a bottom-up stream of sense data, and a top-down stream of predictions. These streams interface at each level of processing, comparing themselves to each other and adjusting themselves as necessary.
The bottom-up stream starts out as all that incomprehensible light and darkness and noise that we need to process. It gradually moves up all the cognitive layers that we already knew existed – the edge-detectors that resolve it into edges, the object-detectors that shape the edges into solid objects, et cetera.
The top-down stream starts with everything you know about the world, all your best heuristics, all your priors, everything that’s ever happened to you before – everything from “solid objects can’t pass through one another” to “e=mc^2” to “that guy in the blue uniform is probably a policeman”. It uses its knowledge of concepts to make predictions – not in the form of verbal statements, but in the form of expected sense data. It makes some guesses about what you’re going to see, hear, and feel next, and asks “Like this?” These predictions gradually move down all the cognitive layers to generate lower-level predictions. If that uniformed guy was a policeman, how would that affect the various objects in the scene? Given the answer to that question, how would it affect the distribution of edges in the scene? Given the answer to that question, how would it affect the raw-sense data received?
Source: Slate Star Codex
Recognizing a face means having a prediction for that face. When you see a new face you have no top-down prediction for what you see. Your mind doesn’t like that. It tries to avoid prediction errors as much as possible. Whenever there’s a big prediction error, your brain triggers attention. Attention is the system by which the brain builds new predictions.
You can experience this right now. This is a picture of a cow:

At first, you just see black spots, but I’m telling you it’s a cow. This constitutes a prediction error. You should see a cow, but you don’t. By paying attention to the picture your brain tries out its different models of “cow” until you finally recognize the cow in the picture (solution here) and the prediction error is eradicated. If no model fits, your brain can create a new one. Making new models is the process of learning.
In predictive processing, movement is a kind of error minimization. Trying to recognize a cow in that picture, is to perform a kind of movement. It’s analogous to recognizing an object by touch. When you touch an object, you can’t just put a finger on it and know what it is. You have to run it through your fingers, move it around, feel its weight, and so forth. You were doing the same kind of thing trying to recognize the cow. You just did it in your mind.
Cortical columns make predictions using dendrites and recognize objects using reference frames.
What we have so far.
Intelligence happens in the neocortex.
The neocortex is composed of 150,000 cortical columns.
A column is composed of 100,000 neurons.
Understanding the column is the key to understanding intelligence.
Columns are prediction machines.
The next step is to figure out how columns make predictions. To do that, I have this intimidating-looking slide for you:

And sorry, I can’t comfort you by saying that it only looks scary, but in principle, it’s super simple. It just isn’t and there’s a lot going on. But what I can do is simplify it a bit and move through one layer at a time.
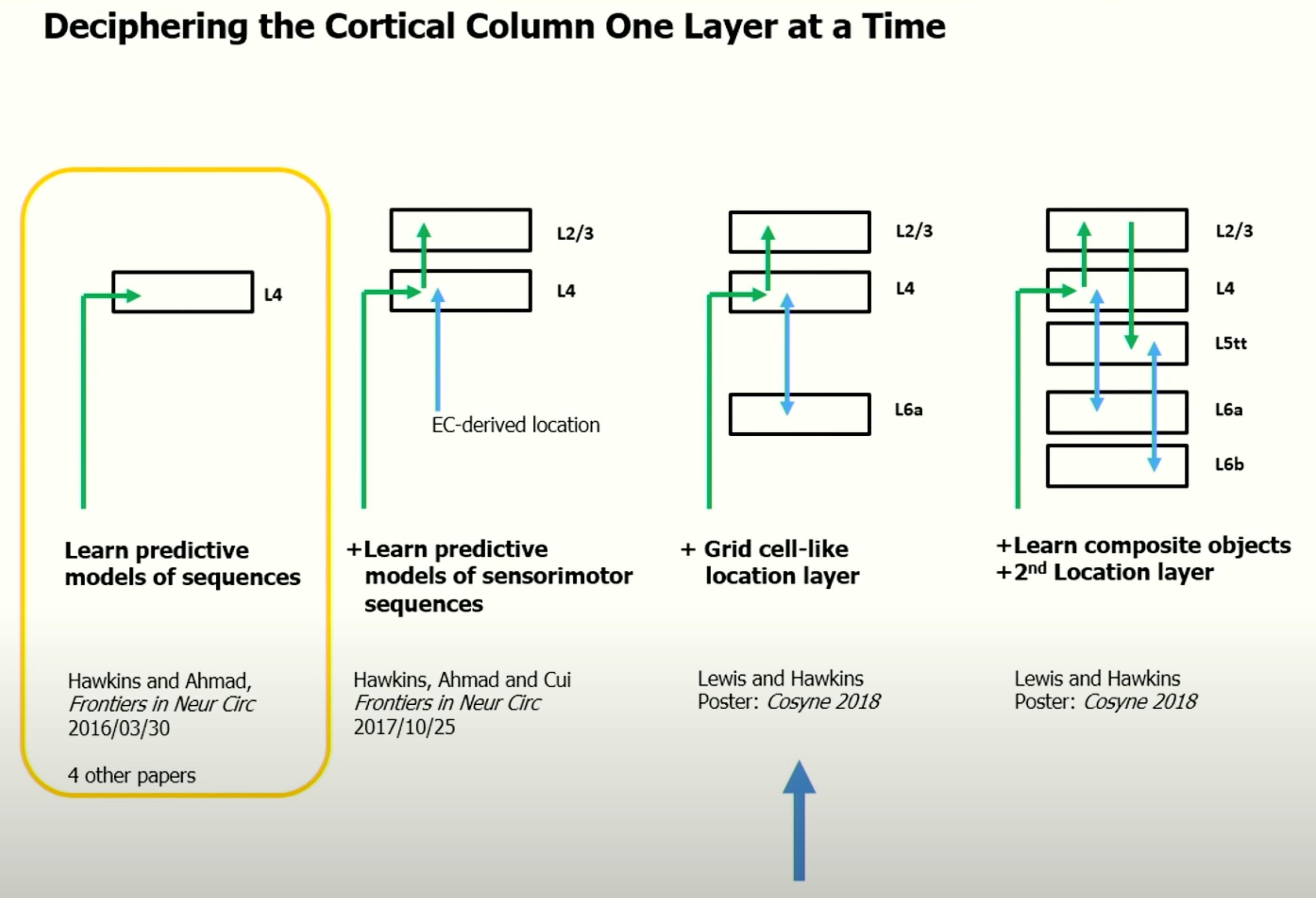
Here are the relevant questions:
How do neurons in L4 predict a sequence (like a melody)?
How do L4 and L2/3 work together to predict objects?
How does L6a supply location information to L4?
I’m not going to get into the fourth part on composite objects, because I don’t understand what’s going on there.
1: How do neurons in L4 predict a sequence?
Is a single neuron already capable of prediction? Apparently yes! It does so with its distal synapses. A synapse is where a neuron gets inputs from another neuron. Only 10% of synapses are proximal (close enough to the cell body to activate the cell). 90% of the synapses are distal (too far away from the cell body to activate the cell).

What is up with those distal synapses? They don’t activate the cell, so why do they even exist? We didn’t know until Jeff Hawkins and Subutai Ahmad came up with a theory in 2016: Why Neurons Have Thousands of Synapses, a Theory of Sequence Memory in Neocortex.
The answer is: distal synapses get the dendrites excited. Dendrites are like cables that stick out of the cell body. And when a dendrite gets excited it increases the overall action potential of the cell - not enough to make it active, but enough to set it into a “ready to fire” state. The “ready to fire” state is the prediction!
This is easier experienced than explained. Read this:

You should be able to hear “brainstorm” in this audio:
Let’s try another:

Now try to hear “green needle” in this one.
Here’s the catch: It is the same audio file both times. It doesn’t matter which audio you play. You will hear either “green needle” or “brainstorm” depending on what you expect to hear. When you expect to hear brainstorm, your “brainstorm-neurons” are in a predictive state and therefore more ready to fire than the other neurons. They will fire first and inhibit your “green-needle-neurons”.1
You can also experience this visually. Does this train arrive or leave?

The answer depends on your expectations, which is to say the state of your neurons. You can make it go either way, just by changing your expectations about it.
The audio examples and the train are not from the book. But they illustrate the concept well and, as far as I understand it, they are a good representation of the underlying concept.
2: How do L4 and L2/3 work together to predict objects?
It goes like this:

The “Input” is Layer 4 and the “Output” is Layer 2/3, inside the same column.
As the finger moves toward the first point a location signal is generated representing where it’s going to touch the cup. The location signal depolarizes the set of cells whose distal dendritic segments match this location. This represents a prediction of the feature that will be sensed. When the finger touches the first spot the sensory input activates a set of mini-columns in the input layer. Cells in these mini columns that were also predicted by the location signal become active. These cells are shown in pink.
This propagates to the output layer and invokes a union of the cells representing all objects which contain this feature at this location. In this case, a cup, ball, and can. What’s happening here is the system is thinking, “based on this sensory feature at this location… what could the object be”?
With this single touch, the system can eliminate many possibilities but cannot disambiguate between these three objects.
Notice that while the input layer changes over time, the output remains stable. This fits our experience. You get many different visual inputs every second. Your eyes move, your head moves, you blink… How come you’re not constantly rediscovering where you are? The answer is in the output layer. My output layer right now says “We’re in the office” and it’s stable. My input layer however goes: "That’s a desk. That’s a window. That’s our coffee cup.” It’s pretty crazy in there. And yet, I don’t have to rediscover where I am all the time, because all these inputs don’t refute what has already been predicted in the output layer, which is “We’re in the office.”
Predictions don’t have to come in one by one. You can get multiple inputs into multiple columns and make multiple predictions all at the same time. When you touch a cup with three fingers instead of one, the columns can work together to recognize the object instantly.

3: How does L6a supply location information to L4?
In the example above, we assumed that L6a knows the location of things. But how exactly does it do that? The answer is reference frames. A reference frame is a grid that is attached to the object you’re trying to recognize. Much like in a 3D modeling program. You flip the thing and the reference frame flips with it. The fact that neurons could hold something as sophisticated as a 3D reference frame is already crazy, but it gets crazier. You don’t just have to know the location of the cup, you have to know the location of each finger relative to it. So not only is there a reference frame attached to the object, but there is a reference frame for each finger that is touching the cup. We’re talking about a reference frame for every single finger. Maybe even for every patch of skin:
Patches of retina are analogous to patches of skin. Each patch of your retina sees only a small part of an entire object, in the same way that each patch of your skin touches only a small part of an object. The brain doesn’t process a picture; it starts with a picture on the back of the eye but then breaks it up into hundreds of pieces. It then assigns each piece to a location relative to the object being observed.
Hawkins, Jeff. A Thousand Brains: A New Theory of Intelligence (p. 50).
Is he saying that a reference frame is attached to every single “pixel” of the visual cortex? It sure sounds like it. Before that insight, you could’ve thought that the main task of the neocortex is processing inputs. Now you should realize that the main task is processing reference frames.
A coffee cup is a thing because it has a reference frame attached to it. Why is your finger a thing? Because it has its own reference frame too. Why is your finger part of you? Because its reference frame is attached to the reference frame of SELF.
Could you attach some object to the reference frame of SELF? Sure thing! The famous rubber hand illusion relies on it. Here’s a taste

The brain constructs reference frames using grid cells and place cells.
Ok, locations are represented by reference frames. How do neurons construct these reference frames? In order to answer that we’ll have to look at how location is represented in the old brain.
Maps in the OLD brain (epistemic status: confident).
The old brain knows where you are relative to your environment. The cells that represent a space are called grid cells. And the cells that represent your location in that space are called place cells.
If I understand it correctly, it goes something like this:

Some very interesting experiments by John O’Keefe, May-Britt Moser, and Edvard Moser show how this grid is built in the brain (they won a Nobel Prize for it).

This is a rat in a box running around with an electrode in its brain. Every time a grid cell is activated, the program puts a dot on that video.
Let the mouse run around for a while, and this is what you get:

See a pattern emerge?

Grid cells create a grid for any room that you are in. And then the place cells tell you what’s in it. Maybe you are looking for your phone. You think you left it in A2. But then you remember it’s actually in B3. You have the same cells representing your phone and the space, but different cells representing the phone’s location.

Maps in the NEW brain (epistemic status: conjecture).
All this grid-cell-place-cell-stuff… we didn’t find it in the neocortex. We found it in the old brain (specifically in the hippocampus and entorhinal cortex). Hawkins’s suggestion here is that a very similar mechanism takes place in the new brain.
It is as if nature stripped down the hippocampus and entorhinal cortex to a minimal form, made tens of thousands of copies, and arranged them side by side in cortical columns. That became the neocortex.
Hawkins, Jeff. A Thousand Brains: A New Theory of Intelligence (p. 62)
The old brain tracks mostly the location of one thing - the body. The new brain seems to track the location of thousands of things, including concepts.
You can establish a grid to learn where things are in space. But you can also do the reverse and figure out what space it is, by checking out the objects. When you know a city well, I could drop you off at any random location and you’d probably be able to figure out where you are. You would go like “hm, this street looks like Salzburg, but it also looks like a place in Regensburg”. What would you do? You would move around and collect more data. While a particular place in a grid might not be unique, the combination of places certainly is.
Less likely to be unique:

More likely to be unique:

This is what happens when you touch a cup and recognize it. Each finger is like a person exploring a city, or like a rat exploring a box.
Here’s Hawkins summarizing it:
If all knowledge is stored this way, then what we commonly call thinking is actually moving through a space, through a reference frame. Your current thought, the thing that is in your head at any moment, is determined by the current location in the reference frame. As the location changes, the items stored at each location are recalled one at a time. Our thoughts are continually changing, but they are not random. What we think next depends on which direction we mentally move through a reference frame, in the same way that what we see next in a town depends on which direction we move from our current location.
Hawkins, Jeff. A Thousand Brains: A New Theory of Intelligence (p. 80).
Concepts, Language, and High-Level Thinking
The point has already been made, but here it is explicitly: Thinking is a type of movement. And the space that we think in, is constructed by the cortical columns, using a grid-cell-type mechanism, which Hawkins calls the reference frame.
We use this trick for much of what we know. For example, we know a lot about photons, and we have knowledge about concepts such as democracy, human rights, and mathematics. We know many facts about these concepts, but we are unable to organize these facts in a way that resembles a three-dimensional object. You can’t easily make an image of democracy. But there must be some form of organization to conceptual knowledge. Concepts such as democracy and mathematics are not just a pile of facts. We are able to reason about them and make predictions about what will happen if we act one way or another.
Our ability to do this tells us that knowledge of concepts must also be stored in reference frames. But these reference frames may not be easily equated to the reference frames we use for coffee cups and other physical objects. For example, it is possible that the reference frames that are most useful for certain concepts have more than three dimensions. We are not able to visualize spaces with more than three dimensions, but from a mathematical point of view they work the same way as spaces with three or fewer dimensions.
[…]
The succession of thoughts that we experience when thinking is analogous to the succession of sensations we experience when touching an object with a finger, or the succession of things we see when we walk about a town.
Hawkins, Jeff. A Thousand Brains: A New Theory of Intelligence.
Of course, reality is not as clear-cut as these examples. Most of it is unconscious. And the dimensions by which you store the knowledge are messy and highly individual. Cortical columns don’t have a preconceived notion of what reference frame they should use. A big part of learning is the column figuring out which reference frames work best for any given piece of knowledge.
Being an expert in a topic is basically equivalent to having built many good reference frames to store knowledge about that topic. All I am doing when explaining things to an audience is sharing my reference frames with them. (A big part of Feynman’s charm was that he was so good at invoking relatable reference frames for abstract concepts. Just look at him here as he calls fire “a big catastrophe” for the atoms.)
It’s called the “thousand brains” theory because your knowledge of an object is distributed among a thousand cortical columns.
One column is enough to recognize a friend’s face. But to store this knowledge in only one column isn’t very robust and prone to error. So the brain does not rely on only one model of anything. You have a thousand models (in a thousand mini-brains) working together to recognize the face. If half of them fail (like it happens when people have strokes etc.) you would still be able to function.
On the other hand, not every column knows every object. Simulations suggest that a column can only hold roughly a hundred objects. Remember, you have 150k columns. It wouldn’t make sense to have all of them hold models for all things.
Just by the way: if you do the stupid math, these numbers would suggest that I can only recognize 15k objects total: 100 objects per column x 150k columns / 1000 columns per object = 15k objects. Seems low. Is this too naive a calculation? There’s probably something I’m doing wrong here.
The binding problem.
Ok, we have a thousand columns that recognize a single object… why then does an object still feel like just one object and not a thousand objects? The answer to that is not clear, but the theory suggests that columns reach a consensus by voting.
Most connections in the cortical columns go up and down the column. You need all that wiring to recognize objects. But there are some that go sideways. These are the ones that vote. If more columns vote “this is a cat” than “this is a dog”, then it’s recognized as a cat.
Hawkins has more to say about how they do all that exactly, but this review is getting looong and I want to move on with my life, so I’ll just leave it at that.
Conclusion
There’s much more to the theory than I could cover. In fact, I limited this review to only the first part of the book “Part 1: A New Understanding Of The Brain". I did so because it’s the most interesting and scientific part of the book. I found the other two parts (“Part 2: Machine Intelligence” and “Part 3: Human Intelligence”) to be less interesting because it’s just the author’s opinions and predictions for intelligence in the future and all I wanted is the science.
If this type of thing interests you, I encourage you to read the thousand brains theory of intelligence. It’s an excellent book with many examples and good explanations. It’s written for a wide audience and is easy to understand. I highly recommend it. And so does Bill Gates.
Thank you to Andrei Albu and Lukas Schott for reading drafts on this.
If this didn’t work for you, I’m sorry. Some people hear only one of the words and can’t imagine it saying anything else.