


A roadmap to the mind
All things from neuroscience to machine learning.

I find myself jumping between disciplines. One day I learn linear algebra, the other I learn brain anatomy, and yet another I do Python exercises. Feels all over the place. So I made a roadmap.
We want to build a mind. There are three main areas of interest: Theory, Computer Science and Neuroscience.
-
Theory. By that, I mean an overarching theory of the mind. It’s an attempt to find a simple explanation for how a mind works. Something like Darwin gave us for evolution. Or Einstein for physics.
A good theory will explain:
(1) Perceiving things
(2) Recognizing things
(3) Paying attention
(4) Continuous learning
(5) Moving around
Predictive processing is (in my opinion) the best theory we have. It treats the brain as a multi-layer prediction machine, with a bottom-up stream of sense data and a top-down stream of predictions. At each layer, the streams meet and make a handshake to decide what’s real. This theory explains almost everything we care about.
Perception (1) is a prediction. Recognition (2) is when you find a prediction that fits your sense data. Recognizing a face means having a prediction for that face. When you see a new face you have no top-down prediction for what you see. Your mind doesn’t like that. It tries to avoid prediction errors or surprisal as much as possible. When there is a prediction error, your brain will trigger attention. Attention (3) is the system by which the brain decides what to predict. If it can’t predict something it will pay attention to it for as long as the prediction fits. If no prediction fits it will create a new prediction. Making new predictions is the process of learning (4). And lastly, movement (5). Movement is a kind of error minimization. When you move your right hand up, your mind is predicting very strongly that your right hand is up, even though it isn’t. It creates a prediction error on purpose. At that moment your prediction is “right-hand-is-up”, the sense data is “right-hand-is-down”. Your body will naturally minimize the error, by moving the hand into the place that was predicted.
I wrote a brief introduction to predictive processing. It’s not the full theory, just a brief introduction. Here’s an image from that post.
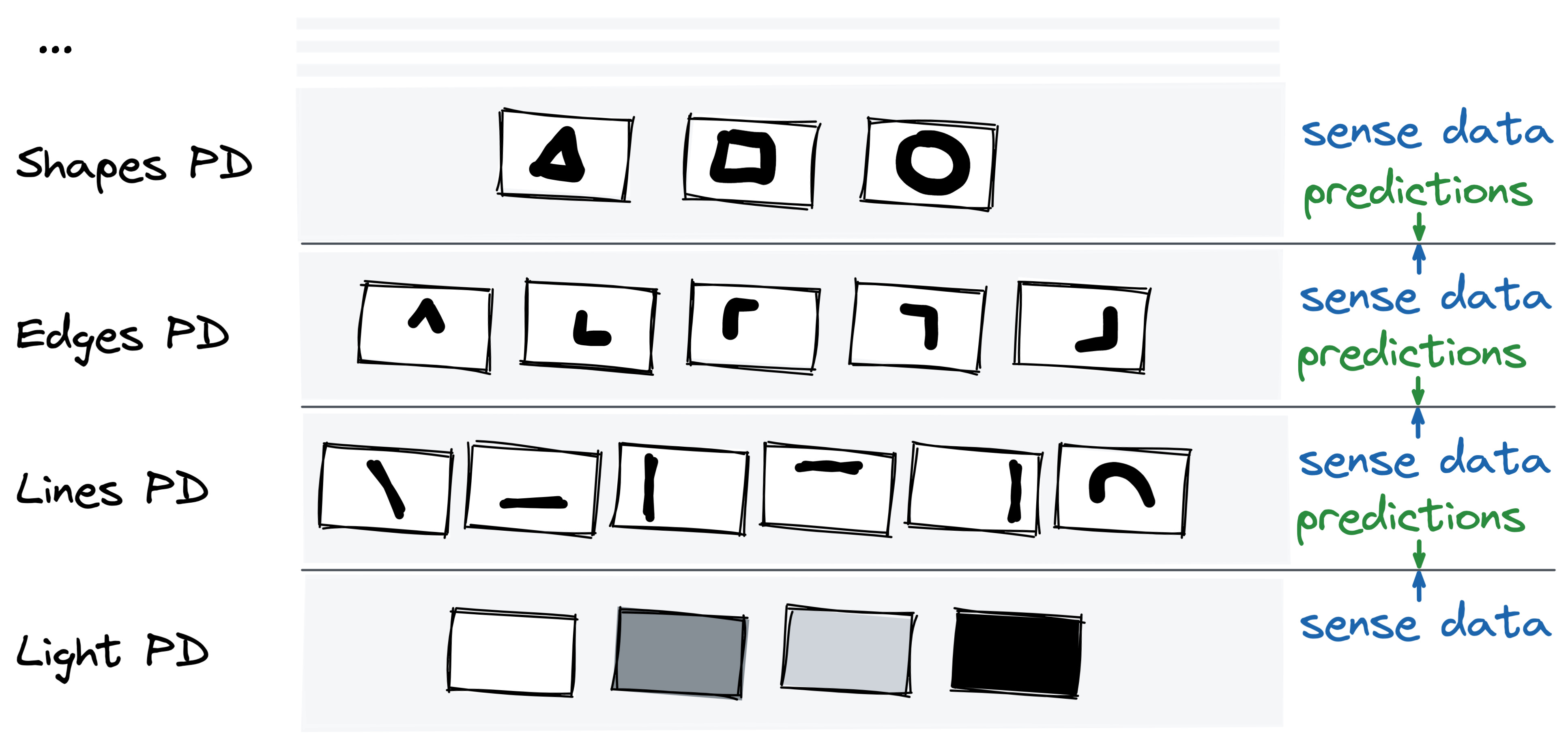
The 1000 brains theory by Jeff Hawkins fits well with predictive processing. Every neuron in your brain represents a prediction or model. It does so by way of excitement. When something looks like the model, the neuron gets a little more excited. That’s perception (1) and recognition (2). When it gets excited enough it gets activated and triggers all neurons that come after. What’s special about this theory is that it distinguished between two types of models. There are place-models and grid-models. Consider how hard it is to recognize a cow from different perspectives. A cow looks very different from the front or back. You need at least one model from each perspective to recognize the cow. That would be hundreds of models, just to recognize the same cow. Wouldn’t it be better to just have one 3D model of a cow and another model for 3D space? That’s exactly what the 1000 brains theory argues our brain does. The cow is the place-model and 3D space is the grid-model. Jeff has an interesting explanation for movement (5). Movement is jumping between places inside a grid-model. We need a model of the self (the place-model) and a model of the world (the grid-model) in order to move. He goes further by saying that thinking is a kind of movement. When we think we move through a multi-dimensional grid, in a similar way we move through space. More on that later. As far as I can tell, the 1000 brains theory doesn’t have much to say about attention (3) or learning (4).
There are more theories I want to look into. In particular whatever Joscha Bach and Anil Seth are up to.
-
Neuroscience tries to understand the mind by understanding the brain. I know very little about the brain or neurons. I will have to do a lot of catching up here. Especially about neurons. I mean just look at it.
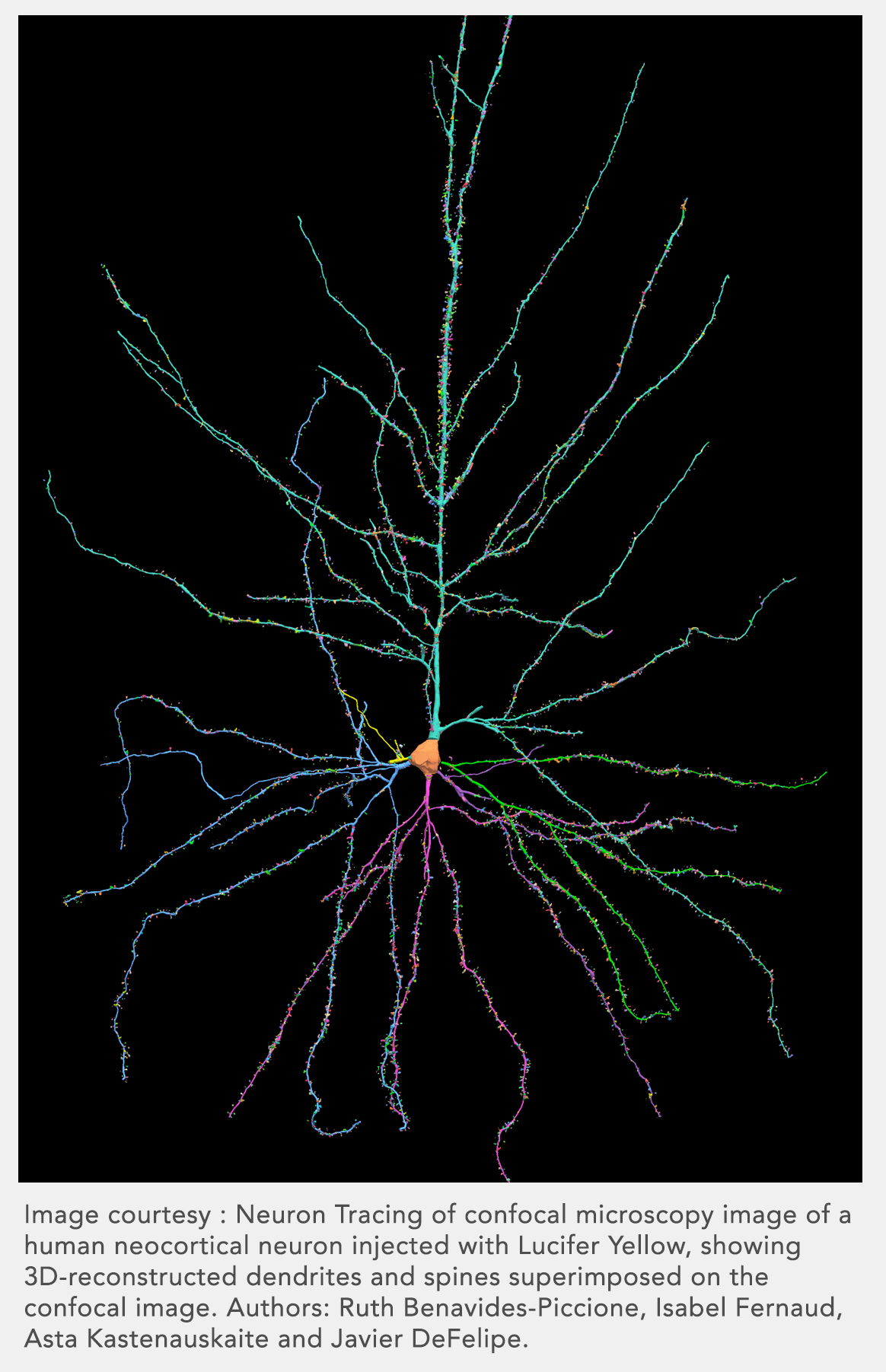
Does that look like a thing that’s easy to understand?
The two important parts are the dendrites and the axon. Dendrites are the things on the bottom. The axon is the thing on the top. Dendrites reach out to other neurons. The little dots on them are Synapses. That is where the dendrite connects with other neurons. One dendrite has about 1000 synapses, which means that it is connected to 1000 other neurons. When the dendrites get strong enough signals they trigger an action potential in the cell body. The action potential flows through the axon and sends it to the dendrites of other cells. This is what that looks like.
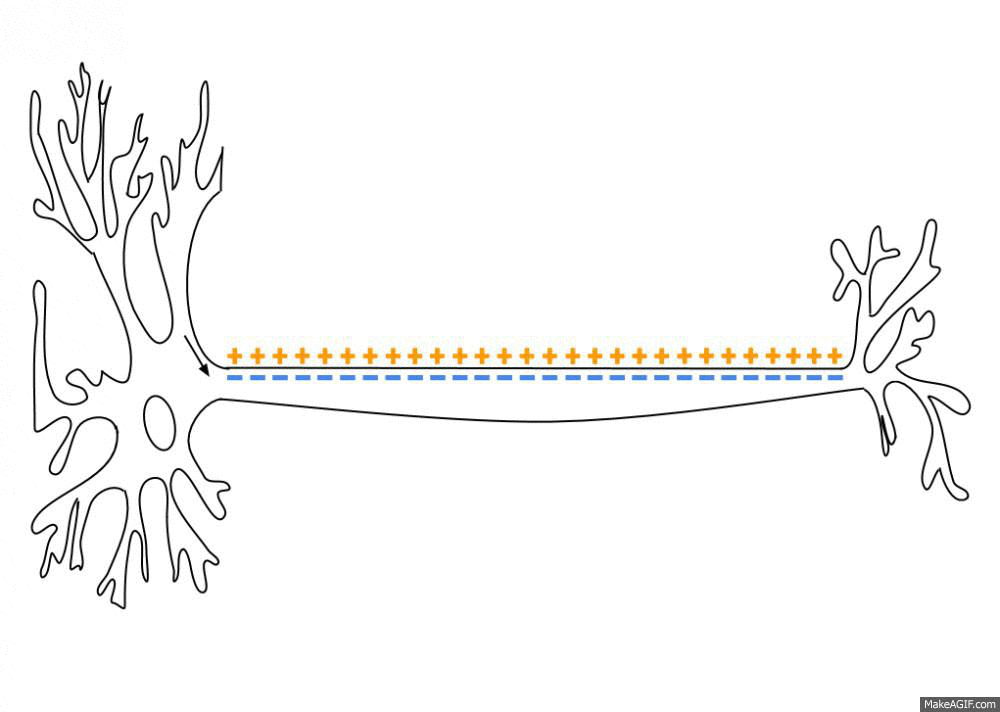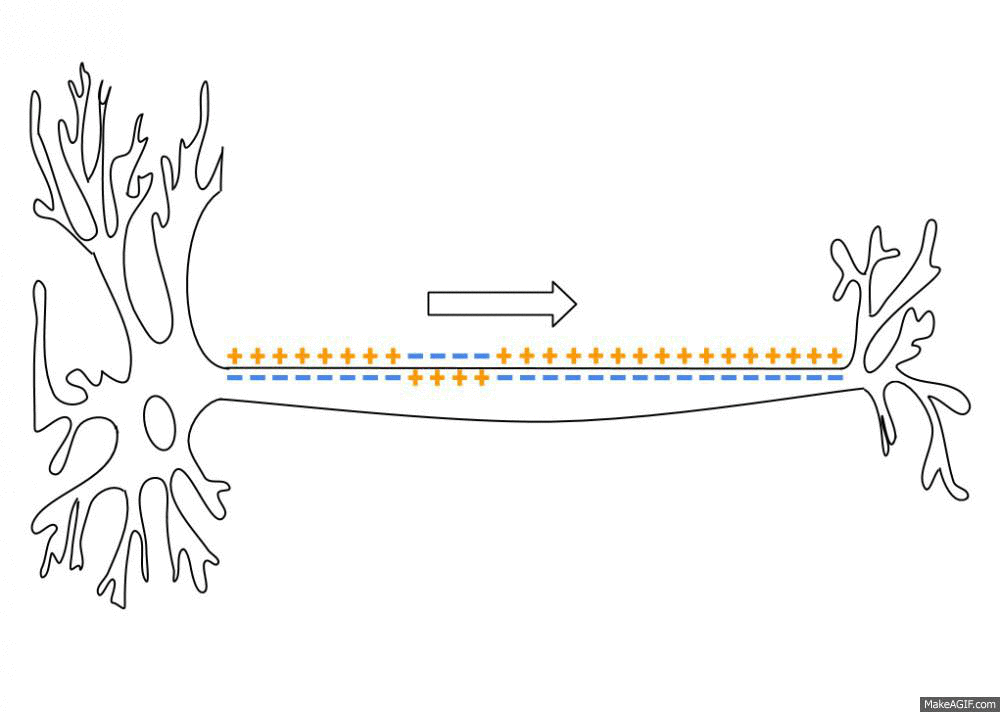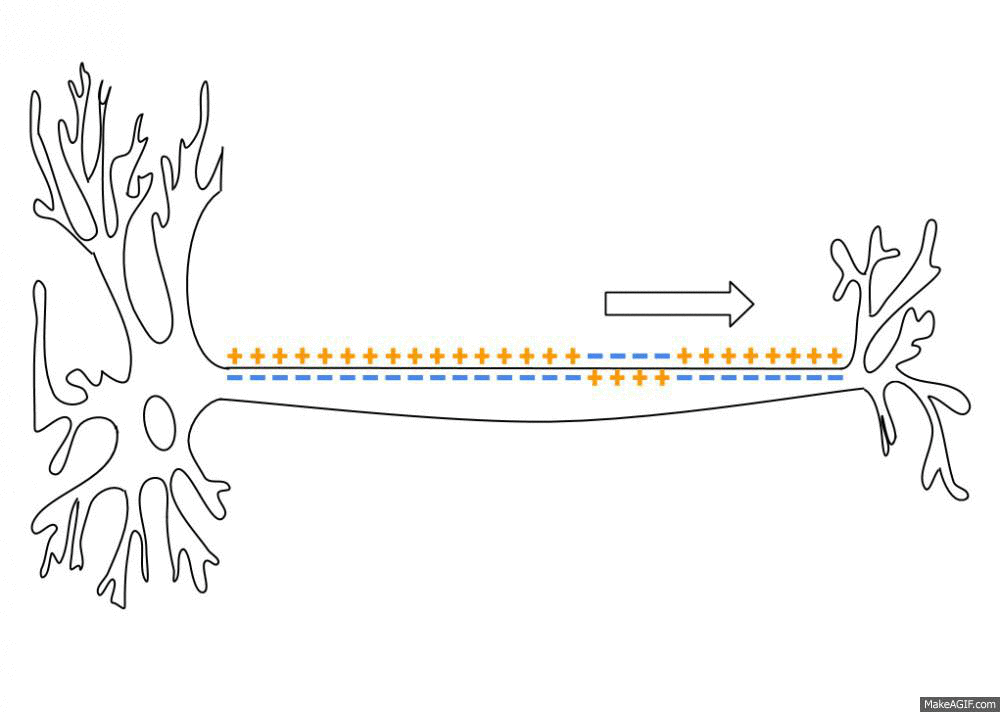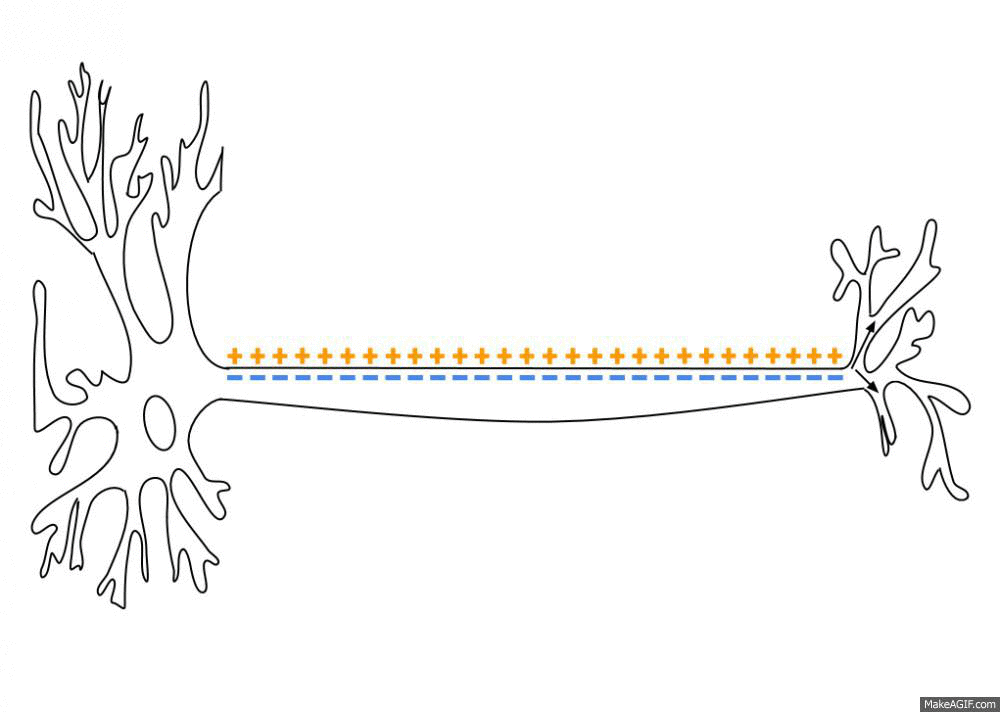
You could say that the dendrites are the input and the axon is the output. Then what is the model? By what mechanism does the neuron compare the input to its prediction?
Suffice it to say that the model is in the dendrites. The dendrites are responsible to get more excited the better the prediction fits. Only when the sense-data is close enough to the prediction, the action potential will flow through the axon. So recognition (2) is done in the dendrites.
And just to make it super-duper clear:

It’s not just neurons that create the mind, it’s the chemicals that surround them. The NMDA glutamatergic system seems to mostly carry the top-down stream of predictions. The AMPA glutamatergic system mostly carries the bottom-up stream. For example: When you take LSD you get a big increase in NMDA and AMPA = lots of data coming in and lots of top-down predictions made = Dendrite and Axons are way too active = Hallucinations. Dopamine likely controls attention and is therefore involved in learning.
I don’t know how all this works. I hope other people do. To learn more, the MIT course about the human brain by Prof. Nancy Kanwisher is a good starting point. And then I’ll have to dig into various types of neurons, computational neuroscience, and dendritic computation. I’ll look into Lisa Feldman Barrett on emotions and into Molecule of More because it was recommended to me. For more on NMDA, AMPA, and the connection to LSD, I’ll check out this paper by Corlett, Frith & Fletcher (2009).
I really hope I don’t discover something about biology that just can’t be translated to computers. Biology is analog, after all. Computers are digital.
-
Computer Science is what we need to implement the theory. The theory gives us a blueprint of the house, computer science gives us the tools to build it.
The most interesting part will be to learn all the artificial neural networks people have already built. The earliest imitation of a neuron is probably the perceptron. The perceptron is a function that returns 1 when the inputs fit a model and 0 when they don’t. But that shit is from the 1940s. Since then there have been multiple interesting innovations on the same idea. A classic machine learning model is basically a bunch of perceptrons put into layers and stacked on top of each other. Backpropagation is the idea of having a function to calculate the inaccuracy of the predictions of the network. Once you have the function you find its minimum. You do that by tweaking the neurons so that the inaccuracy gets smaller with each tweak. This idea, plus an increase in computation power made machine learning viable. Convolutional neural networks help to detect features (like edges and lines) in images. This innovation made object recognition in images possible. Transformers mimic attention. When you have a piece of text, it is difficult to let a computer know what this text refers to. For example: “Kevin is a nice boy. He likes to play football.” The “He” refers to Kevin. It is very difficult to make a network understand that. Before transformers people tried recurring neural networks. Apparently, nobody does that anymore. And then there’s reinforcement learning, which is the idea of having computers learn by playing. Every time it makes a good move, it gets a reward. Let a model play against itself a million times you get a model that makes good moves.
This is oversimplified and there’s much more to learn. Thankfully, there are so many fascinating places to learn about machine learning.
The problem with machine learning is that none of the modern neural networks do what we actually care about. I repeat:
(1) Perceiving things
(2) Recognizing things
(3) Paying attention
(4) Continuous learning
(5) Moving around
I don’t think neural networks actually perceive or recognize things. Yes, you can give them a picture and they will tell you what’s on that picture. But they don’t have a sense of what that thing in the picture really is. Let me explain…
Here are some examples of what a modern neural network is able to recognize.

Yes, it’s impressive. But all it does is compare a given image to all the other images it was trained on. If your image looks similar to other images that are labeled “leopard”, then it will tell you it’s a leopard. This is very different from how humans recognize things. Humans have a sense of what a leopard is. We know that an animal is a thing that exists in the world. We can infer what that thing looks like from different perspectives. Remember the cow example in the 1000 brains theory? Neural networks don’t do that. They don’t know what “a thing” is or what “the world” is.
This was beautifully shown by Katz & Barbu. If you want a model to recognize objects from angles that it hasn’t seen before, it gets in big trouble. Performance drops from 71% to 25% correct.
Here on the left-hand side, you see the kind of images the network was trained on (ImageNet). On the right-hand side, you see the images produced by Katz & Barbu (ObjectNet).

So yeah. Modern neural networks are cool, but they are not a mind. At least not yet.
Computer science is not only about knowledge, but also about skill. The core skill is to know how to make a processor make calculations. Python is the easiest way to do that. I really hope that the classical ones-and-zeros processors are suited for the task. If we find out that they’re not, I might have to get into processors. (God, I really don’t want to get into processors.) There are some analog processors that are designed for AI. I guess that’s what I’d start checking out if we go down that road
-
Where do we go from here?
Sorry, this is a lot. I just needed to write down everything that’s on my mind right now.
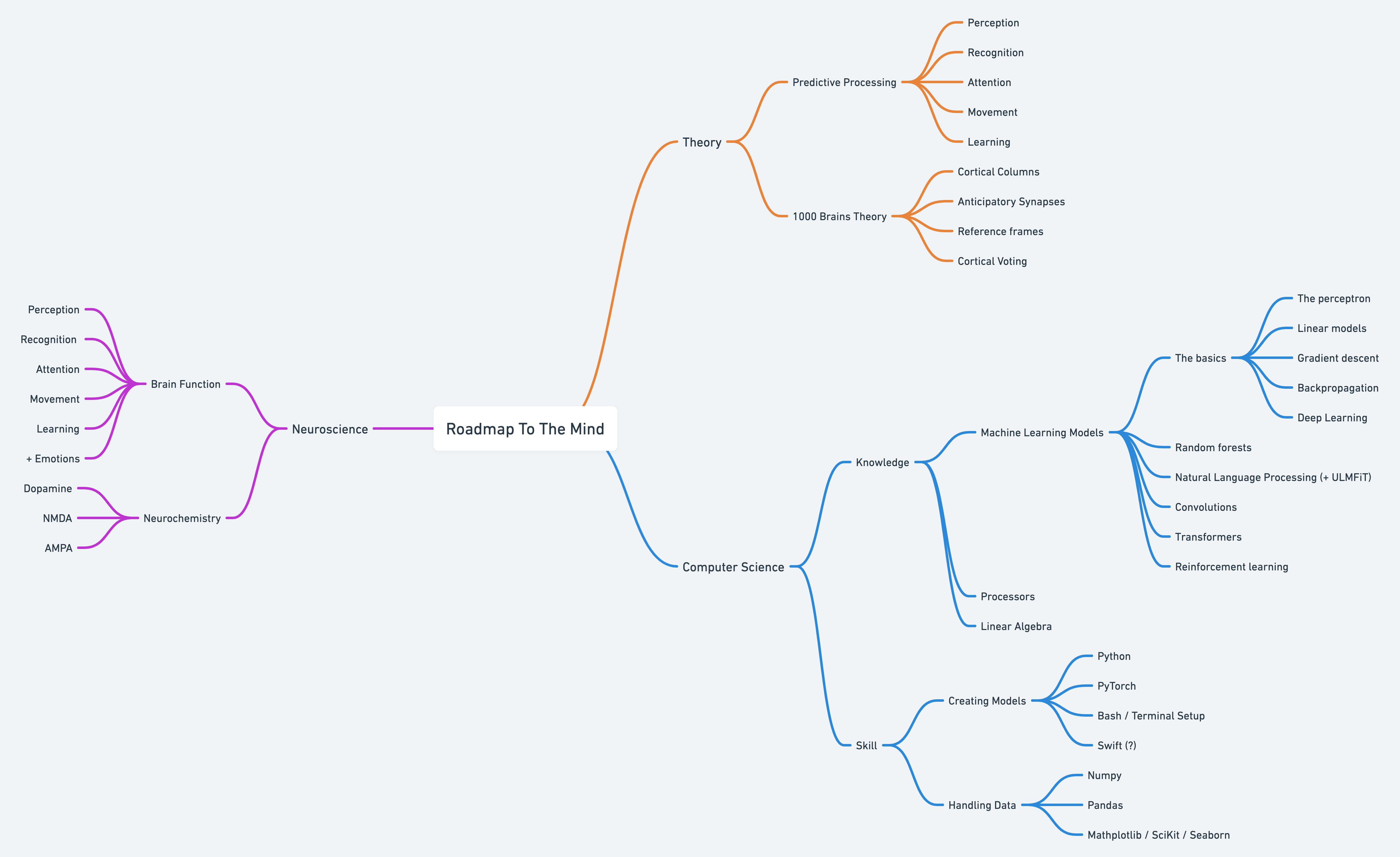
As much as I would like to, I can’t learn everything at once. First, I’ll focus on studying the two main theories. Once I understand the theories I can start studying the brain. At the same time, I can get really good at the kind of programming that is needed to build a mind. Python seems like the right place to start. Once I feel comfortable with the basics I’ll start building models. Step by step I should catch up with the status quo in machine learning.
At some point, study and practice will meet. I hope to develop my own unique theory of the mind. And by the time I have it, I hope to also have the skills to build it.
Sounds like a plan.